Author: Nomi L. Harris, Sierra Moxon, Deepak Unni, Karamarie Fecho, Chris Mungall on March 13, 2023 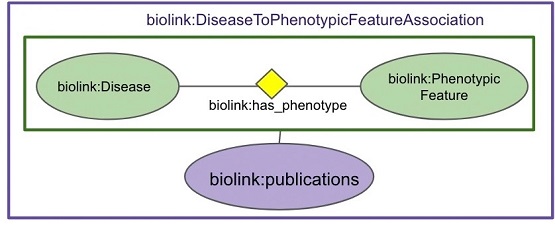
Treating rare and multigenic diseases requires researchers to synthesize data from an ever-increasing number of specialized sources. Clinical observations, genomic analyses, model organism phenotypes, drug efficacy and approval statuses, pathway and reaction data, behavior studies: these are just a subset of the data necessary to understand and treat complex conditions. In addition, large amounts of data that could help bridge gaps in understanding continue to accumulate in unstructured textual formats (like publications). Searching and compiling information from unstructured text is improving, but still presents barriers in navigating between data sources and publications. As a result, information that aids in answering translational questions can hide in plain sight within a corpus of published research and siloed data sources. To help elucidate these complex connections in clinical, biomedical, and translational science, an increasing number of researchers are adopting graphs for knowledge representation. Graph-based data models illuminate the interconnectedness between core biomedical concepts, enable data structures to be easily updated, and support intuitive queries, visualizations, and inference algorithms. However, knowledge discovery across these ‘knowledge graphs’ (KGs) has remained difficult, due in large part to the lack of a universally accepted, open-access model for standardization across biomedical KGs.
Biolink Model is an open-source data model that addresses these issues and can be used to formalize the relationships between data structures in translational science. A recent article in Clinical and Translational Science (CTS), “Biolink Model: A universal schema for knowledge graphs in clinical, biomedical, and translational science,” was one of the top-10 most-downloaded articles in 2022, as well as one of the top three articles in terms of global public attention. This demonstrates a clear interest among translational scientists in exploring standards for reconciling heterogenous data from multiple sources.
The core of Biolink Model is a set of hierarchical, interconnected classes (or categories) and relationships between them (or predicates), representing biomedical entities such as gene, disease, chemical substance, anatomical structure, and phenotype. The model also provides a catalog of class and edge attributes, and associations that guide how to represent entities that are related to one another. The model provides a scaffolding for connecting data sources and knowledge graphs. As an open-source community of experts from a wide variety of domains, Biolink Model developers are committed to providing the shared language needed to interoperate.
A related paper published in the same issue of CTS describes the Translator project, funded by the National Center for Advancing Translational Sciences (NCATS). The Translator system is a KG-based platform for combining, searching, and reasoning over biomedical data to "translate" it into insights intended to augment human reasoning and accelerate translational science. The Translator Consortium is one of many programs that have adopted Biolink Model to interoperate between knowledge sources and reason across KGs. The Translator system has been applied to generate insights across diverse use cases, including Fanconi anemia, asthma, primary ciliary dyskinesia, multiple sclerosis, and drug-induced liver injury.
More than simply a data model, Biolink Model helps to forge collaborations between people from different professional backgrounds. “It is inspiring to see experts from a wide variety of domains communicate and collaborate on a shared model,” said Sierra Moxon, data architect and software developer at Lawrence Berkeley National Laboratory. “Biolink Model establishes a common language to communicate with, and that’s the first step to solving hard problems together.”

The comment feature is locked by administrator.